Note
Go to the end to download the full example code.
1. Exploratory Data Analysis
import matplotlib.pyplot as plt
from ai4water.eda import EDA
from ai4water.utils import TrainTestSplit
from easy_mpl import hist
from easy_mpl import plot
from easy_mpl import scatter
from easy_mpl import boxplot
from easy_mpl.utils import create_subplots
from easy_mpl.utils import map_array_to_cmap, process_cbar
from utils import read_data
from utils import COLUMN_MAPS
from utils import set_rcParams, version_info
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/sklearn/experimental/enable_hist_gradient_boosting.py:15: UserWarning: Since version 1.0, it is not needed to import enable_hist_gradient_boosting anymore. HistGradientBoostingClassifier and HistGradientBoostingRegressor are now stable and can be normally imported from sklearn.ensemble.
warnings.warn(
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_clustering.py:35: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _pt_shuffle_rec(i, indexes, index_mask, partition_tree, M, pos):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_clustering.py:54: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def delta_minimization_order(all_masks, max_swap_size=100, num_passes=2):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_clustering.py:63: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _reverse_window(order, start, length):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_clustering.py:69: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _reverse_window_score_gain(masks, order, start, length):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_clustering.py:77: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _mask_delta_score(m1, m2):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/links.py:5: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def identity(x):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/links.py:10: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _identity_inverse(x):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/links.py:15: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def logit(x):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/links.py:20: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _logit_inverse(x):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_masked_model.py:363: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _build_fixed_single_output(averaged_outs, last_outs, outputs, batch_positions, varying_rows, num_varying_rows, link, linearizing_weights):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_masked_model.py:385: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _build_fixed_multi_output(averaged_outs, last_outs, outputs, batch_positions, varying_rows, num_varying_rows, link, linearizing_weights):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_masked_model.py:428: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _init_masks(cluster_matrix, M, indices_row_pos, indptr):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/utils/_masked_model.py:439: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _rec_fill_masks(cluster_matrix, indices_row_pos, indptr, indices, M, ind):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/maskers/_tabular.py:186: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _single_delta_mask(dind, masked_inputs, last_mask, data, x, noop_code):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/maskers/_tabular.py:197: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _delta_masking(masks, x, curr_delta_inds, varying_rows_out,
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/maskers/_image.py:175: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def _jit_build_partition_tree(xmin, xmax, ymin, ymax, zmin, zmax, total_ywidth, total_zwidth, M, clustering, q):
/home/docs/checkouts/readthedocs.org/user_builds/xyzxyzxyz/envs/latest/lib/python3.9/site-packages/shap/explainers/_partition.py:676: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def lower_credit(i, value, M, values, clustering):
The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
IPython could not be loaded!
datasets module is deprecated. Please install water-datasets and import
corresponding dataset from there.
for k,v in version_info().items():
print(k, v)
python 3.9.20 (main, Nov 5 2024, 16:07:55)
[GCC 11.4.0]
os posix
ai4water 1.07
easy_mpl 0.21.4
SeqMetrics 2.0.0
tensorflow 2.10.1
keras.api._v2.keras 2.10.0
numpy 1.21.6
pandas 1.5.3
matplotlib 3.7.1
h5py 3.13.0
sklearn 1.3.1
seaborn 0.13.2
ngboost 0.4.1
shap 0.41.0
set_rcParams()
COLUMN_MAPS_ = {v:k for k,v in COLUMN_MAPS.items()}
COLUMN_MAPS_['ww_conc'] = "Wastewater Conc."
COLUMN_MAPS_['sonic_pd'] = "Sonicator Power"
COLUMN_MAPS_['h20_conc.'] = 'H2O2 Conc.'
data = read_data()
data_area = read_data(target='Area (ABD) Mean')
data_both = read_data(target=['Area (ABD) Mean', 'Efficiency'])
print(data.shape)
(314, 7)
data_both.describe()
eda = EDA(data=data, save=False, show=False)
ax = eda.correlation(figsize=(8,8), square=True,
cbar_kws={"shrink": .72},
cmap="Spectral"
)
ax.set_xticklabels(ax.get_xticklabels(), fontsize=12, weight='bold', rotation=70)
ax.set_yticklabels(ax.get_yticklabels(), fontsize=12, weight='bold')
plt.tight_layout()
plt.show()
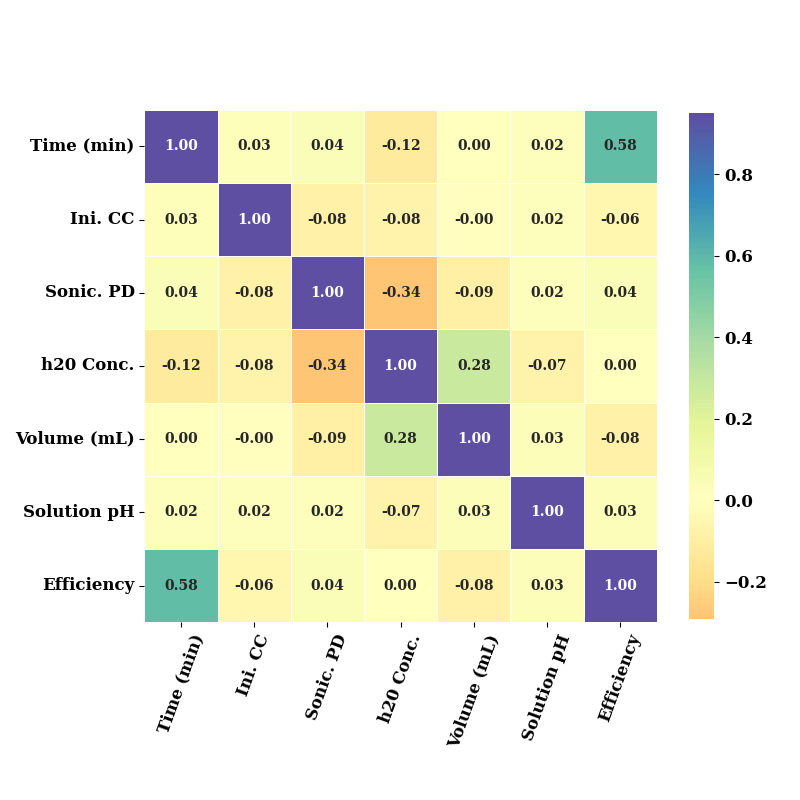
Correlation
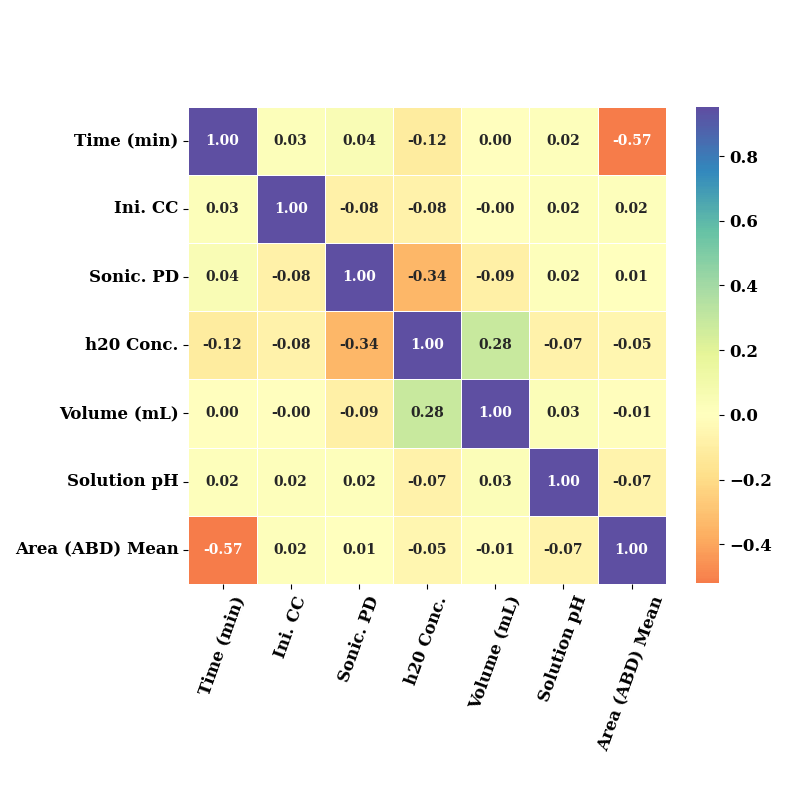
eda = EDA(data=data_area, save=False, show=False)
ax = eda.correlation(figsize=(8,8), square=True,
cbar_kws={"shrink": .72},
cmap="Spectral"
)
ax.set_xticklabels(ax.get_xticklabels(), fontsize=12, weight='bold', rotation=70)
ax.set_yticklabels(ax.get_yticklabels(), fontsize=12, weight='bold')
plt.tight_layout()
plt.show()
eda = EDA(data=data_both, save=False, show=False)
ax = eda.correlation(figsize=(8,8), square=True,
cbar_kws={"shrink": .72},
cmap="Spectral"
)
ax.set_xticklabels(ax.get_xticklabels(), fontsize=12, weight='bold', rotation=70)
ax.set_yticklabels(ax.get_yticklabels(), fontsize=12, weight='bold')
plt.tight_layout()
plt.show()
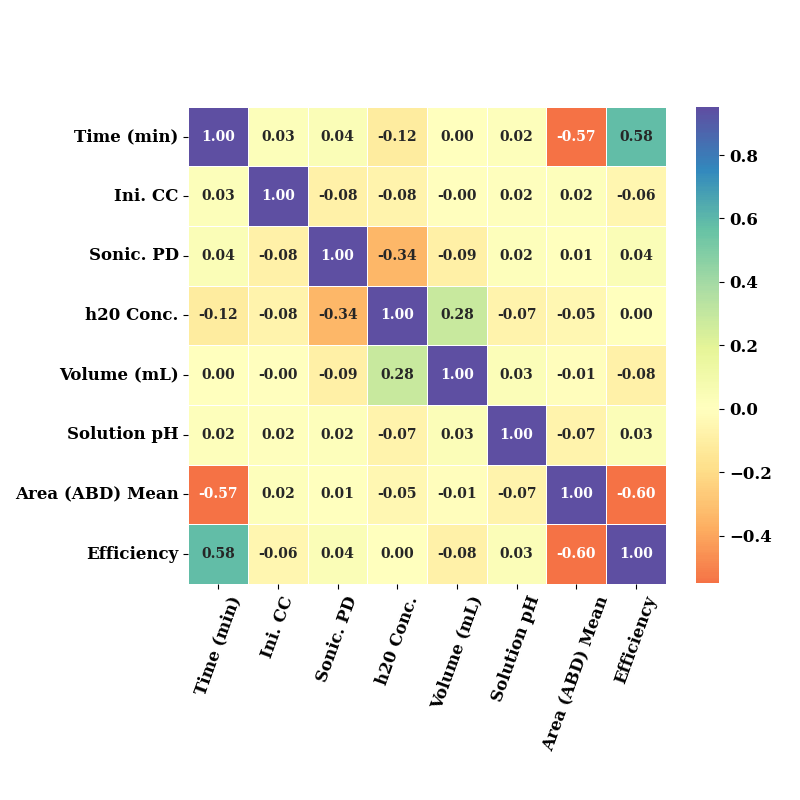
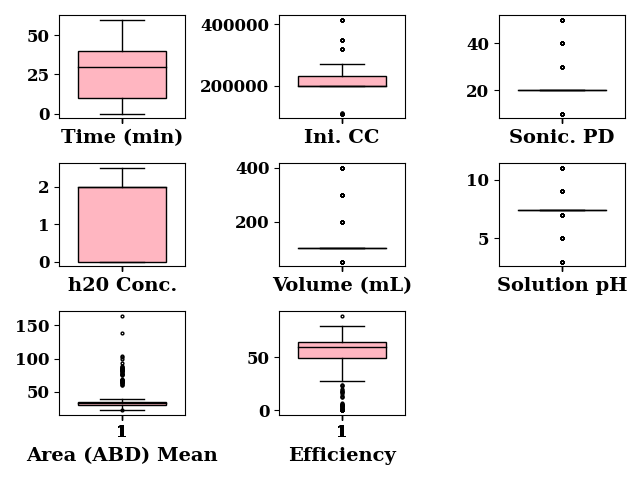
Distribution
f, axes = create_subplots(data_both.shape[1], sharex="all")
for col, ax in zip(data_both.columns, axes.flatten()):
boxplot(
data_both[col], labels=col, ax=ax, show=False,
fill_color="lightpink",
patch_artist=True,
widths=0.7,
flierprops=dict(ms=2.0),
medianprops={"color": "black"},
)
ax.set_xlabel(col)
plt.tight_layout()
plt.show()
xticks (2) and xticklabels (1) dont match
xticks (3) and xticklabels (1) dont match
xticks (4) and xticklabels (1) dont match
xticks (5) and xticklabels (1) dont match
xticks (6) and xticklabels (1) dont match
xticks (7) and xticklabels (1) dont match
xticks (8) and xticklabels (1) dont match
train_count, test_count, _, _ = TrainTestSplit(seed=313).split_by_random(
data['Efficiency'],
)
ax, _ = boxplot([train_count, test_count],
flierprops=dict(ms=2.0),
widths=0.6,
labels=["Train", "Test"],
showmeans=True,
patch_artist=True,
fill_color=["darkorange", "peachpuff"],
medianprops={"color": "black", 'linewidth': 2},
capprops={"linewidth":2}, whiskerprops=dict(linewidth=2),
line_width=2.,
meanprops={"markerfacecolor": "black",
"markeredgecolor": 'black',
"marker": "o"},
show=False
)
ax.tick_params(labelsize=12)
ax.set_xticklabels(["Train", "Test"], fontsize=12)
ax.grid(visible=True, ls='--', color='lightgrey')
plt.show()
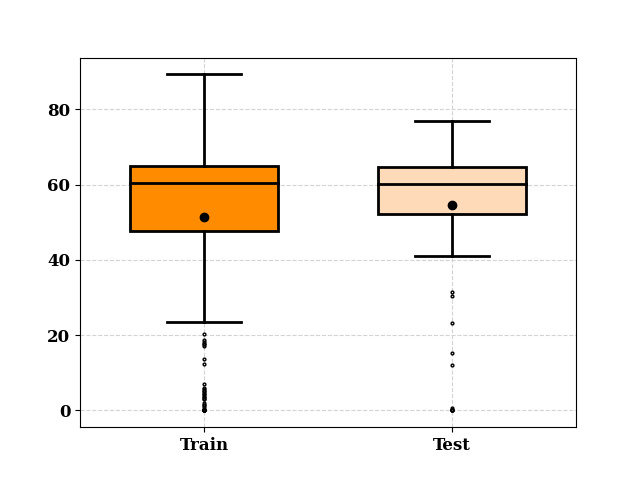
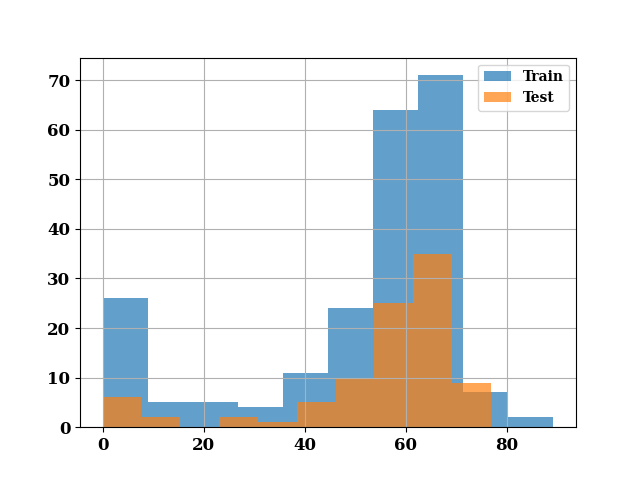
_ = hist([train_count.values, test_count.values],
labels=["Train", "Test"], alpha=0.7)
train_area, test_area, _, _ = TrainTestSplit(seed=313).split_by_random(
data_area['Area (ABD) Mean'],
)
ax, _ = boxplot([train_area, test_area],
flierprops=dict(ms=2.0),
widths=0.6,
labels=["Train", "Test"],
showmeans=True,
patch_artist=True,
fill_color=["darkorange", "peachpuff"],
medianprops={"color": "black", 'linewidth': 2},
capprops={"linewidth":2}, whiskerprops=dict(linewidth=2),
line_width=2.,
meanprops={"markerfacecolor": "black",
"markeredgecolor": 'black',
"marker": "o"},
show=False
)
ax.tick_params(labelsize=12)
ax.set_xticklabels(["Train", "Test"], fontsize=12)
ax.grid(visible=True, ls='--', color='lightgrey')
plt.show()
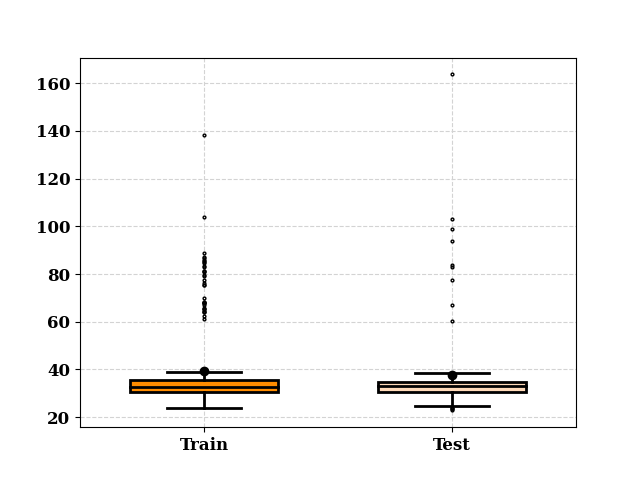
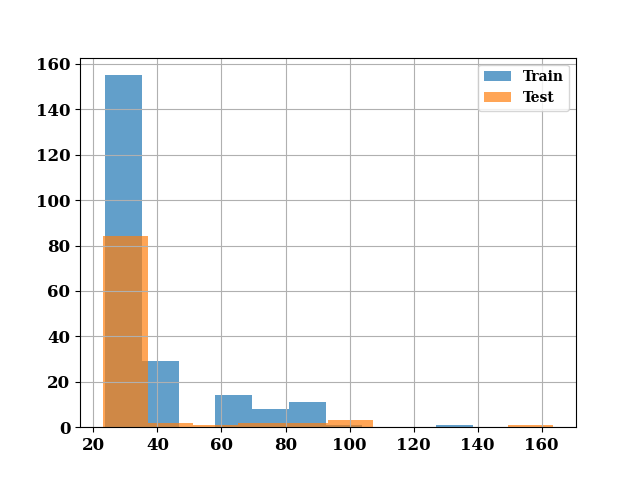
_ = hist([train_area.values, test_area.values],
labels=["Train", "Test"], alpha=0.7)
line plot
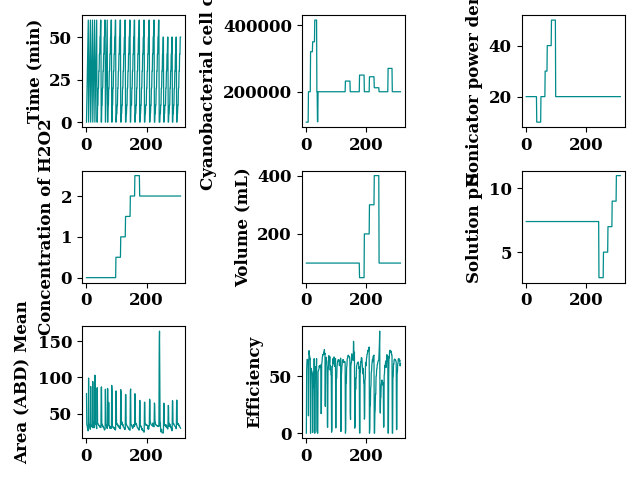
fig, axes = create_subplots(data_both.shape[1])
for ax, col, label in zip(axes.flat, data_both, data_both.columns):
plot(data_both[col].values, ax=ax,
ax_kws=dict(ylabel=COLUMN_MAPS_.get(col, col),
ylabel_kws={"fontsize": 12, 'weight': 'bold'},),
lw=0.9,
color='darkcyan', show=False)
plt.tight_layout()
plt.show()
Feature Interaction
def draw_scatter(target, ax, label="Efficiency"):
ax.grid(visible=True, ls='--', color='lightgrey')
c, mapper = map_array_to_cmap(data[target].values, "inferno")
if target in ["Sonic. PD", "Volume (mL)"]:
ylabel = None
else:
ylabel = label
if target in ['Solution pH', 'Volume (mL)']:
xlabel = "Time (min)"
else:
xlabel = None
ax_, _ = scatter(data_both['Time (min)'], data_both[label],
color=c, alpha=0.5, s=40, ec="grey", zorder=10,
ax_kws=dict(logy=True, ylabel=ylabel,
ylabel_kws={"fontsize": 12, 'weight': 'bold'},
top_spine=False, right_spine=False,
xlabel=xlabel,
xlabel_kws={"fontsize": 12, 'weight': 'bold'}),
ax=ax, show=False)
process_cbar(ax_, mappable=mapper, orientation="vertical", pad=0.1,
border=False,
title=COLUMN_MAPS_.get(target, target),
title_kws=dict(fontsize=12))
return
f, all_axes = create_subplots(5, sharex="all", facecolor="#EFE9E6", figsize=(9, 6))
targets = ['Ini. CC', 'Sonic. PD', 'h20 Conc.', 'Volume (mL)', 'Solution pH']
for col, axes in zip(targets, all_axes.flatten()):
draw_scatter(col, axes)
plt.tight_layout()
plt.show()
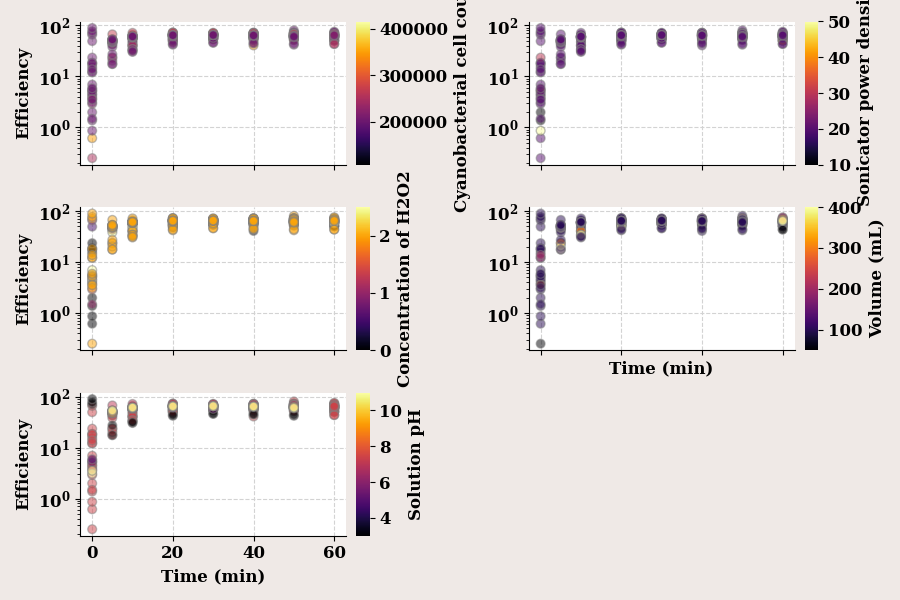
`process_cbar` is deprecated as a function name; use `add_cbar` instead.
f, all_axes = create_subplots(5, sharex="all", facecolor="#EFE9E6", figsize=(9, 6))
targets = ['Ini. CC', 'Sonic. PD', 'h20 Conc.', 'Volume (mL)', 'Solution pH']
for col, axes in zip(targets, all_axes.flatten()):
draw_scatter(col, axes, label="Area (ABD) Mean")
plt.tight_layout()
plt.show()
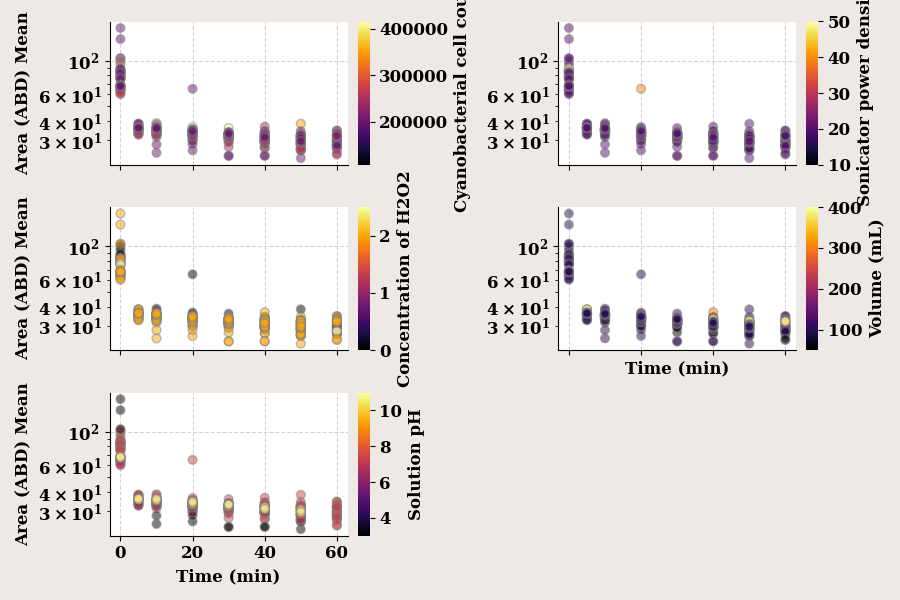
`process_cbar` is deprecated as a function name; use `add_cbar` instead.
Total running time of the script: (0 minutes 8.514 seconds)